Adaption des PoCs an die Cloud
Contents
Adaption des PoCs an die Cloud#
Webscrapping#
Für das Webscrapping wird der Code aus dem Proof of Concept auf einer Virtuellen Maschine mittels Cronjob gestartet.
Mit der Syntax */2 * * * * wird die Datei alle 2 Minuten ausgeführt und damit stetig ein Link aus der Linkliste aufgerufen. Die Zeitverzögerung dient dazu das Erkennen des Scrappers zu vermeiden.
Google Cloud Limits#
Die im Proof of Concept verwendete Youtube API und die Sentiment-Analyse sind Teil der Google Cloud, welche bei der Erstregistrierung ein Startguthaben von 300 USD anbietet. Um dieses möglichst auszunutzen, wird wie erläutert, die weitere Scrapping-Infrastruktur ebenfalls in der Google Cloud gehalten.
Neben den Kosten für die virtuelle Machine sind die Youtube-API und Sentiment-Analyse die limitierenden Faktoren.
Ein kostenloser Account darf maximal 10.000 Abrufe über die Youtube-API anfordern. Dies enthält die Suche nach der Video-ID und den Abruf der Kommentare.
Die Sentiment-Analyse ist sehr kostspielig mit 2 USD pro 1.000 Abfragen. Eine Abfrage darf maximal eintausend Zeichen enthalten. Zusätzliche Zeichen werden als eigene Abfrage gezählt.
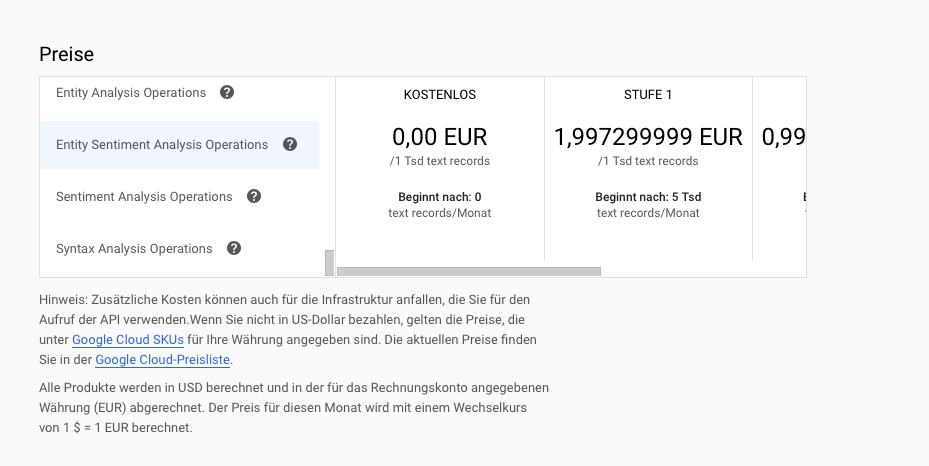
Fig. 11 Screenshot Google Cloud Sentiment Preise [cloud.google.com, n.d.]#
Youtube-API#
Die Youtube-API wird im Rahmen der kostenlosen Nutzung auf 10.000 Quotas pro Tag begrenzt. Quotas können als Währung verstanden werden. Eine Suchanfrage kostet 100 Quotas. Je Videoabruf wird ein Quota fällig. Der Tagesverbrauch wird über eine Abklingzeit im Verlauf zurückgesetzt. D.h. man muss nicht zwingend 24 Stunden warten bis eine weitere Nutzung möglich ist.
Um das Limit nicht zu überschreiten, werden über im Cronjob pro Durchlauf zwei Dokumente der unverarbeiteten Videos geladen. Es werden ca. 2000 Kommentare pro Video erwartet. Unter Berücksichtigung der Limitierung kann der PoC-Code ca. 20 Videos pro Tag bearbeiten. Für die ersten 50 der 468 Videos werden alle Kommentare abgerufen, um die Funktionalität zu belegen. Diese betreffen die Woche 1 bis 4. Näheres dazu wird im Kapitel Analyse erläutert.
Die ca. 20 Videos ergeben sich aus 10.000 Quotas im Verhältnis zu den Kosten pro Video: \(10000 / (2000 / 20 * 4 + 100)\)
Alleine für den Abruf der Kommentare sind ca. 24 Tage notwendig. Um die lange Laufzeit zu vermeiden werden nur die ersten 80 Kommentare abgerufen. Für die verbleibenden 418 Videos ergibt sich damit ein Wert von 96 Stück pro Tag.
Der Cronjob wird alle 4 Minuten mit folgenden Code ausgeführt. Über den ergänzten try-except-Block in get_videoID_by_title() wird ein permanentes Durchlaufen des Codes verhindert. Die Instanz zum Cronjob wird über einen Instanzterminplan täglich von 23 bis 8 Uhr gestartet.
*/4 * * * * export DISPLAY=:0 && export PATH=$PATH:/usr/local/bin && cd /home/markusarmbrecht/ && /home/markusarmbrecht/miniconda3/bin/python sentiment.py >> outputs.txt
Alternativ könnte ein Instanzterminplan und @reboot-Cronjob angelegt werden. In diesem Fall muss eine Lösung fürs Quotalimit gefunden oder eine kostenpflichtige Abfrage genutzt werden.
@reboot export DISPLAY=:0 && export PATH=$PATH:/usr/local/bin && cd /home/markusarmbrecht/ && /home/markusarmbrecht/miniconda3/bin/python sentiment.py >> outputs.txt
Die sentiment.py enthält den Code aus dem Proof of Concept. Jedoch mit 2 Dokumenten, wie unten dargestellt wird, und ein Limit auf 80 Kommentare je Video.
'''
Auszug
'''
myList = mycoll.find({'videoID':{'$exists':False}})[0:2]
for doc in myList:
mongo_obj_id = doc['_id'] # ObjectID von mongoDB speichern
myTitle = doc['team1']+' '+doc['team2']+' '+doc['week']+' Highlights | NFL 2021'
vid_id = get_videoID_by_title(myTitle)
if vid_id == "NoQuota":
print(vid_id)
break
def get_videoID_by_title(video_title):
'''
takes: video_title as string
returns: videoId as string
describtion:
builds a connection to Youtube Data API and executes a search method to list results.
searches for channelId from NFL-Youtube Channel, for videos only
returns videoID for most relevant search result
'''
try:
youtube = build('youtube', 'v3',
developerKey=api_key)
response = youtube.search().list(
part='snippet',
q=video_title,
channelId='UCDVYQ4Zhbm3S2dlz7P1GBDg', # NFL Channel ID
type='video',
order='relevance', # Default Value = relevance
maxResults=1
).execute()
return response['items'][-1]['id']['videoId']
except:
return "NoQuota"
Die folgende Grafik zeigt den beschriebenen Kontingentverbrauch.
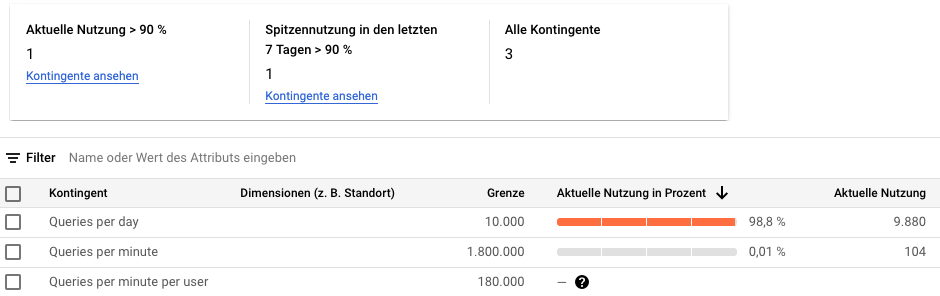
Fig. 12 Screenshot Youtube API Kontingent#
Sentiment Analyse#
Jedoch ist die Youtube API nicht der Flaschenhals des Projekts. Die Sentimentanalyse ist kostspielig und für die absolute Menge an Kommentaren wird das Guthaben nicht ausreichen.
Im Durchlauf für die Wochen 1 bis 4 sind ca 150 USD an Kosten angefallen. Ein Erwartungswert wurde mit einem Schätzwert von ca 2000 Kommentaren je Video ermittelt: \(50 * 2000 * 0,002 = 200\)
Nach der Drosselung auf 80 Kommentare pro Video können folgende Kosten erwartet werden.
\(418 Videos * 4 PageTokens * 20 Kommentare = 33.440 Kommentare\)
\(33.440 * 0,002 = 66,88\)
Die Limitierung erfolg über die Funktion get_comments() aus dem Proof of Concept. Dabei wird der Counter auf 4 gesetzt, um den While-Loop nach 80 Kommentaren zu verlassen. (siehe nachfolgenden Code)
myList = mycoll.find({'videoID':{'$exists':False}})
def get_comments(vidId):
'''
takes: youtube video id as string, global api_key as string
returns: list of toplevel-comments under video (no replies)
describtion:
builds a connection to Youtube Data API and executs commentsThreads().list() methods
iterates over response from api request and stores displayed text as string in an list
breaks if no NextPageToken is provided. Thus end of comments is reached.
breaks if counter < threshold-value prevent Youtube out of quota error
returns list with comments
'''
# list for several pages
comments = list()
counter = 4 # entfällt beim 50-Video Durchlauf
# get youtube access
youtube = build('youtube', 'v3',
developerKey=api_key)
# get response
response = youtube.commentThreads().list(
part='snippet',
videoId=vidId,
textFormat='plainText'
).execute()
# iterate over comments and append to output list
while True:
for item in response['items']:
comments.append(item['snippet']['topLevelComment']['snippet']['textDisplay'])
counter -= 1 # Entfällt beim 50-Video Durchlauf
if counter < 1:
break
if 'nextPageToken' in response:
response = youtube.commentThreads().list(
part='snippet',
pageToken=response['nextPageToken'],
videoId=vidId
).execute()
else:
break
return comments
Die folgende Grafik zeigt den Traffic in der Google Cloud. Der Verbrauch der Youtube-API ist in blau und die der Sentiment Analyse in orange eingezeichnet.
Zu erkennen ist der rasante Anstieg der Youtube-Fehlerquote, sobald die Youtube Quota aufgebraucht ist. Mit etwas mehr Code könnte auch ein Abschalten der Instanz getriggert werden, wenn die “Out of Quota”-Fehlermeldung zurückgegeben wird.
Bei der orangenen Linie ist zu erkennen, dass der Code wie geplant nicht zur Sentiment Analyse durchläuft.
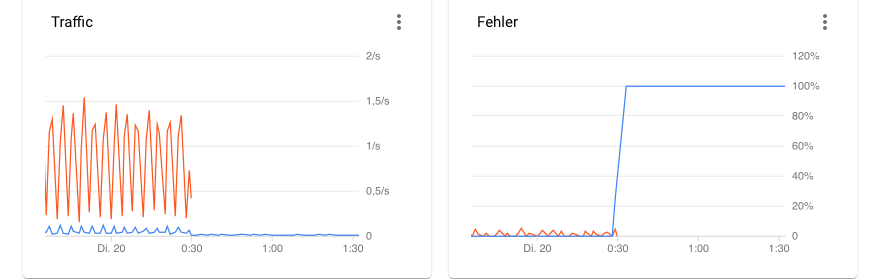
Fig. 13 Screenshot Google Cloud Traffic#