Zukünftige Daten
Contents
Zukünftige Daten#
Konzept#
Um zukünftige Daten zu scrappen, muss der Code leicht angepasst werden. Die folgende Abbildung zeigt eine ereignisgesteuerte Prozesskette (EPK) zur Gestaltung.
Die Spielwoche geht von Freitag bis Donnerstag. Das Skript für das Scrapping und zum Befüllen der Linkliste wird abhängig von diesen Zeitplan ausgeführt. Zusätzlich wird überprüft ob die Daten bereits zur Verfügung stehen und der Sentiment-Abruf erfolgen kann. Bestenfalls verzögert man den Abruf noch um ein paar Tage, um eine angemessene Anzahl an Kommentaren abrufen zu können.
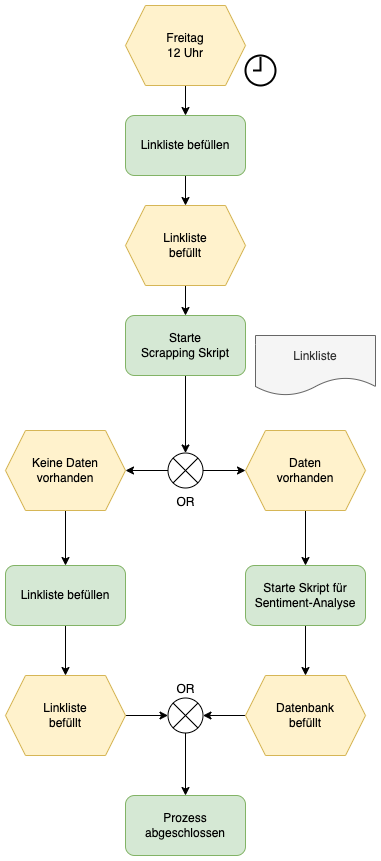
Fig. 14 EPK zum Abruf zukünftiger Daten#
Die nachfolgende Codeänderungen sind notwendig, um die geplante EPK umzusetzen. Das Zeitereignis soll mit einem Cronjob und dem Instanzenterminplan getriggert werden.
Dazu wird auf die bekannte Vorgehensweise zurückgegriffen. Nachdem der Instanzenterminplan die Instanz startet, wird folgender Cronjob ausgelöst.
@reboot sleep 300 & ... & .../python scrapping.py >> output_log.txt
Ergänzend sollte eine Abschaltung der Instanz über ein Shutdown-Skript programmiert werden.
Linkliste befüllen#
Wie in Kapitel POC beschrieben ist, setzt sich die URL auf der offiziellen Seite der NFL nach einem festen Schema zusammen. Werden über das Schema Links zu Wochen aufgerufen, welche noch nicht existieren, wird “No Games Available” ausgegeben (siehe Abbildung).

Mit BeautifulSoup kann ermittlet werden, ob eine Seite diesen Einträg enthält. In diesem Fall wird der Link vorerst nicht zur Linkliste ergänzt. Das Skript zum Befüllen der Linkliste muss ebenfalls abhängig vom Zeitplan der Spielwache gestartet werden.
Änderung Scrapping#
Das Scrapping kann abhängig vom Inhalt der Linkliste gesteuert werden. Diese Methode wird bereits zum Stoppen des Skripts eingesetzt.
Statt eines print-Statements kann ein Shutdownskript ausgeführt werden, welches die Instanz herunterfährt [cloud.google.com, n.d.]. Der nachfolgende Code verwendet jedoch einen lokalen sudo-Befehl für Linux VM [cloud.google.com, n.d.].
if os.stat('link_list.txt').st_size == 0:
os.system("sudo shutdown -h now")
else:
url = get_current_week()
soup = get_page(url)
containers = soup.find_all('div', class_="nfl-c-matchup-strip nfl-c-matchup-strip--post-game")
for i in containers:
myDict = get_teams_scores(i)
myDict['year'] = url.split('/')[-3]
myDict['week'] = 'Week ' + re.sub(r'[^\d]+', '', url.split('/')[-2])
mycoll.insert_one(myDict)
print('succesful scrapping run')
Anpassungen Sentiment-Skript#
Zu Beginn des Sentiment-Skripts wird geprüft, ob in der Datenbank Dokumente ohne das Feld videoID vorhanden sind. Dieser Teil des Codes kann mit einer if-else-Abfrage geprüft werden. Diese ruft eine Funktion auf, solange die Liste länger als Null ist.
Zur Abfrage wird von einer for-Loop auf while-Loop gewechselt und der letzte Eintrag in der Liste abgerufen. Sobald nur noch Dokumente mit Feld videoID vorhanden sind kann das oben beschriebene Shutdown-Skript ausgeführt werden.
myList = mycoll.find({'videoID':{'$exists':False}}) # Anzahl der Dokumente entfällt
while myList > 0:
myList.pop(-1)
### Unterhalb der alte Code ###
mongo_obj_id = doc['_id'] # Store ObjectID from mongoDB
myTitle = doc['team1']+' '+doc['team2']+' '+doc['week']+' Highlights | NFL 2021' # Generate Title String to retrieve videoID
vid_id = get_videoID_by_title(myTitle)
counter = 0
for comment in get_comments(vid_id):
counter += 1
myDict = dict()
# Retrieve old information
myDict = doc
myDict['videoID'] = vid_id
# Add new information / generate one doc per entity
myDict['comment'] = comment
try:
entList = get_entity_sentiment(comment)
for ent in entList:
del myDict['_id'] # Delete ObjectId that is returned after first insert_one() function call
myDict['entity'] = ent['entity']
myDict['salience'] = ent['salience']
myDict['score'] = ent['score']
myDict['magnitude'] = ent['magnitude']
mycoll.insert_one(myDict)
except:
print('Comment is not in English.') # Catch Comments that are not in English. Those cannot be analysed by our sentiment-function.
mycoll.delete_one({'_id':ObjectId(mongo_obj_id)}) # Delete Object bei ID
### Unterhalb neuer Code ###
os.system("sudo shutdown -h now")