Kommentare und Sentiment
Contents
Kommentare und Sentiment#
import json
import os
from googleapiclient.discovery import build
from google.cloud import language_v1
import pandas as pd
from pymongo import MongoClient
from bson.objectid import ObjectId
'''
Zur Installation von Google spezifischen Bibliotheken
'''
# !pip install --upgrade google-api-python-client
# !pip install --upgrade google-cloud-language
Verbindung zu mongodb und Google Cloud#
Zunächst werden die Verbindungen zur Cloud-Infrastruktur erstellt.
Die JSON-Datei API_Data enthält den API Key zur Youtube-API und den mongodb-Zugang. Die Google Sentiment Analyse erfolgt mit Application Credentials welche als Systemvariablen eingelesen werden.
api_key = json.load(open('API_Data.json'))['ytDataAPI'] # key for Youtube Data API
mongodb_pass = json.load(open('API_Data.json'))['mongoDB_pass'] # password mongodb user
os.environ["GOOGLE_APPLICATION_CREDENTIALS"]="green-reporter-369217-84ed773093b1.json" # expose google service account for sentiment analysis
client = MongoClient(mongodb_pass)
db = client.nfl_data
mycoll = db.games
Youtube Part I: Schnittstelle Webscrapping und Video-ID#
Je Spiel muss das relevante Highlightvideo auf Youtube aufgerufen werden. Der Abruf erfolgt mit der Video-ID, welche durch die nachfolgende Funktion gesucht wird.
Nachdem die Verbindung zur Youtube-API aufgerufen wird, erfolgt eine Suchanfrage mit search().list(). Die Anzahl der Suchergebnisse wird auf eins beschränkt. Zur Risikominimierung wird die Suche auf die Channel-ID des NFL-Youtubekanals begrenzt und eine Sortierung nach Relevanz verwendet.
def get_videoID_by_title(video_title):
'''
takes: video_title as string
returns: videoId as string
describtion:
builds a connection to Youtube Data API and executes a search method to list results.
searches for channelId from NFL-Youtube Channel, for videos only
returns videoID for most relevant search result
'''
youtube = build('youtube', 'v3',
developerKey=api_key)
response = youtube.search().list(
part='snippet',
q=video_title,
channelId='UCDVYQ4Zhbm3S2dlz7P1GBDg', # NFL Channel ID
type='video',
order='relevance', # Default Value = relevance
maxResults=1
).execute()
return response['items'][-1]['id']['videoId']
video_title = 'Tennessee Titans vs. Green Bay Packers | 2022 Week 11 Game Highlights'
print('Video Titel: %s \nVideoID: %s'%(video_title,get_videoID_by_title('Tennessee Titans vs. Green Bay Packers | 2022 Week 11 Game Highlights')))
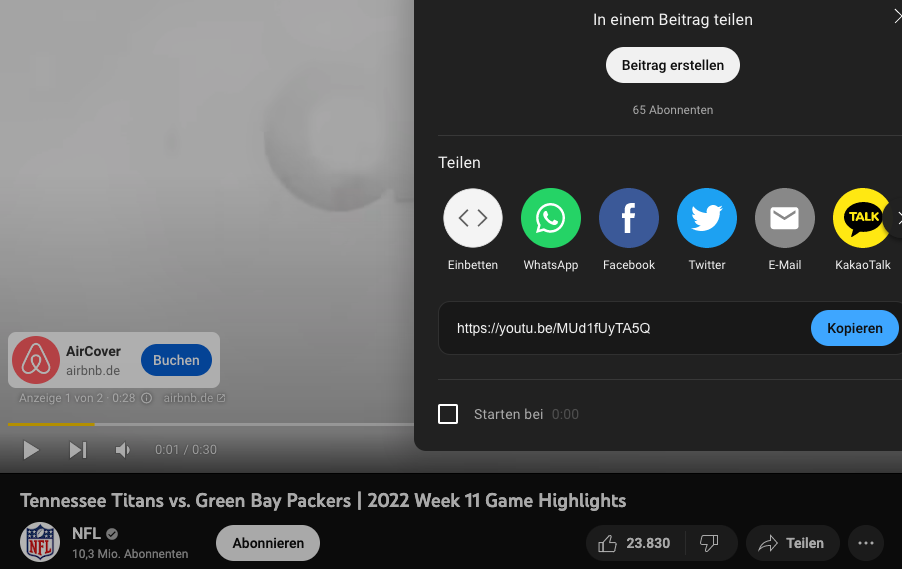
Video Titel: Tennessee Titans vs. Green Bay Packers | 2022 Week 11 Game Highlights
VideoID: MUd1fUyTA5Q
Nachfolgende Abbildungen zeigen einmal die Channel-ID, welche aus dem Quellcode entnommen werden kann und die Verifizierung zur oben ausgegeben Video-ID über den Teilen-Link.
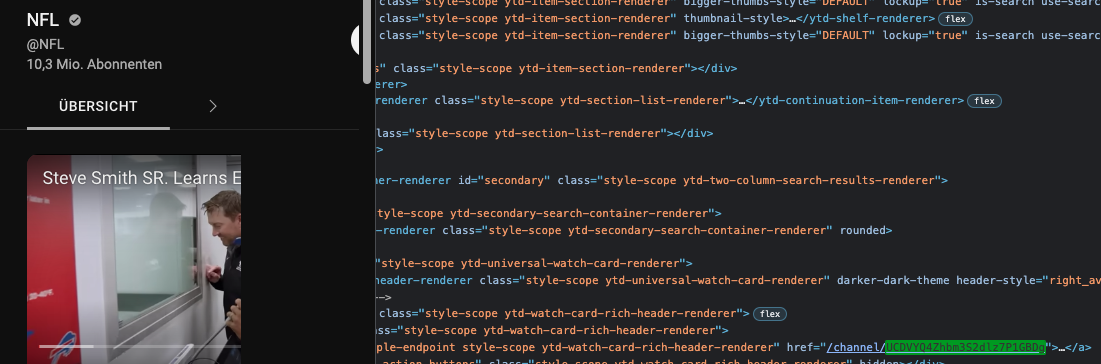
Fig. 6 Screenshot Youtube NFL [Youtube NFL, n.d.]#
Youtube Part II: Kommentare zur Video-ID#
Nachdem die Video-ID bekannt ist, können die Kommentare aufgerufen werden. Dies erfolgt mit der Funktion commentThreads().list(). Zurückgegeben wird ein Dictionary mit Kommentar-Items.
In dieser Arbeit liegt der Fokus auf den TopLevel-Kommentaren, welche einer Liste hinzugefügt werden. Je Abruf über die API wird ein Quota verbraucht. Ein Abruf gibt 20 Kommentare und einen nextPageToken zurück, welcher zum Abruf der nächsten 20 Kommentare benötigt wird. Dieser Token entfällt, sobald die letzten Kommentare abgerufen werden. Für den Proof of Concept wird ein Counter eingesetzt, um den Verbrauch von Quota gering zu halten.
def get_comments(vidId):
'''
takes: youtube video id as string, global api_key as string
returns: list of toplevel-comments under video (no replies)
describtion:
builds a connection to Youtube Data API and executs commentsThreads().list() methods
iterates over response from api request and stores displayed text as string in an list
breaks if no NextPageToken is provided. Thus end of comments is reached.
breaks if counter < threshold-value prevent Youtube out of quota error
returns list with comments
'''
# list for several pages
comments = list()
counter = 1
# get youtube access
youtube = build('youtube', 'v3',
developerKey=api_key)
# get response
response = youtube.commentThreads().list(
part='snippet',
videoId=vidId,
textFormat='plainText'
).execute()
# iterate over comments and append to output list
while True:
for item in response['items']:
comments.append(item['snippet']['topLevelComment']['snippet']['textDisplay'])
counter -= 1
if counter < 1:
break
if 'nextPageToken' in response:
response = youtube.commentThreads().list(
part='snippet',
pageToken=response['nextPageToken'],
videoId=vidId
).execute()
else:
break
return comments
Im nächsten Schritt wird das Video-ID von oben verwendet, um die Anzahl der ersten Kommentarabfrage und die ersten beiden Kommentare abzurufen.
Die Abbildung zeigt die letzten Kommentare zum Zeitpunkt der Code-Ausführung unter dem Video.
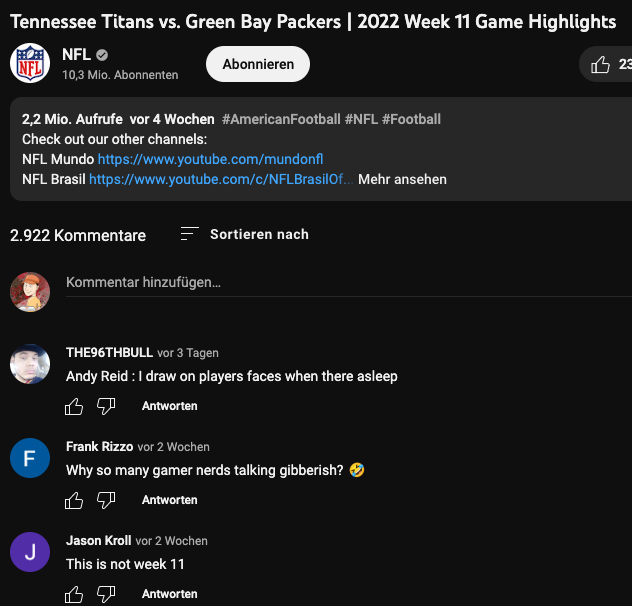
video = 'MUd1fUyTA5Q' # Dieser String kommt aus Youtube I
myComments = get_comments(video)
print('Anzahl Kommentare:',len(myComments))
print('-'*20)
print('Erster Kommentare:',myComments[0])
print('-'*20)
print('Zweiter Kommentare:',myComments[1])
Anzahl Kommentare: 20
--------------------
Erster Kommentare: Andy Reid : I draw on players faces when there asleep
--------------------
Zweiter Kommentare: Why so many gamer nerds talking gibberish? 🤣
Sentiment Analyse#
Je Kommentar wird die Stimmung (das Sentiment) ausgelesen. Ziel des Projektes ist die Stimmung zu den spielenden Teams auszuwerten. Es besteht die Möglichkeit, dass in den Kommentaren auch Sentimente zu anderen Teams oder Sachverhalten (z.B. Half-Time-Show, Schiedsrichter, Fans, etc.) ausgewertet werden, weil diese im Kontext genannt werden.
Beispielsweise könnte unter dem Video zu “Titans vs Rams” darüber gesprochen werden, dass ein Spieler bereits beim Spiel gegen die Packers schlecht performt hat. Um diesen verzerrenden Zusammenhang abzumildern, wird mit der Google Cloud Funktion „Entity-Sentiment“ gearbeitet. Diese extrahiert neben dem Sentimentwert auch die vorhandenen Entitäten mit folgenden Kennzahlen:
Salience
Score
Magnitude
Salience stellt die Relevanz der Entität im Text dar. Die Skala beträgt 0.0 bis 1.0. Desto höher der Werte, umso relevanter ist die Entität. Score ist der eigentliche Sentimentwert in Bezug auf die Entität. Er liegt zwischen -1 und 1 für negativ bis positiv. Jedoch tendiert auch eine gemischte Stimmung zum Wert Null. Magnitude dient zur Evaluation des Scores und seiner Tendenz zu Null bei gemischten Dokumenten. Weniger emotionale Kommentare haben einen geringen Magnitude-Wert. Ein hoher Wert der Emotionalität bei geringen Sentiment lässt auf einen Kommentar mit gemischter Stimmung schließen. [cloud.google.com, n.d.]
Die folgende Funktion gibt die Entität mit den jeweiligen Werten als Dictionary zurück.
def get_entity_sentiment(myText):
'''
takes: string with comment
returns: dictionary with entity and sentiment-values
'''
client = language_v1.LanguageServiceClient()
doc = language_v1.Document(content=myText,type_=language_v1.types.Document.Type.PLAIN_TEXT)
response = client.analyze_entity_sentiment(request={'document':doc, 'encoding_type':language_v1.EncodingType.UTF8})
myList = list()
for ent in response.entities:
myDict = dict()
sent = ent.sentiment
myDict['entity'] = ent.name
myDict['salience'] = ent.salience
myDict['score'] = sent.score
myDict['magnitude'] = sent.magnitude
myList.append(myDict)
return myList
Nachfolgend wird ein echter, eher neutraler Kommentar dargestellt. Im Anschluss folgen drei erfundene Kommentare: ein positiver, ein negativer und ein Kommmentar mit gemischter Stimmung.
Es wird gezeigt, dass der neutrale Kommentar viele Null-Werte enthält. Jedoch die Titans als relevanteste Entität erkannt werden.
Für den negativen Kommentar werden eindeutige Sentiment-Score und Salience-Werte ausgegeben. Der magnitude-Wert zeigt auch eine deutliche Emotionalität an.
Der gemischte Kommentar erkennt im Vergleich zum nachfolgenden positiven Kommentar die Titans als relevanteste Entität mit weniger Magnitude und Sentiment, weil die Stimmung gemischt ist.
myTest = get_entity_sentiment('The Titans showed the Dallas Cowboys and the NFL how to finish a game, especially against Aaron Rodgers.')
myTest2 = get_entity_sentiment('Titans are stupid.')
myTest3 = get_entity_sentiment('Titans are the best team ever but that player-guy was stupid.')
myTest4 = get_entity_sentiment('Titans are the best team ever.')
print('Neutral Comment')
print(myTest)
print('-'*20)
print('Negative Comment')
print(myTest2)
print('-'*20)
print('Positive Comment with Negative Component')
print(myTest3)
print('-'*20)
print('Positive Comment')
print(myTest4)
Neutral Comment
[{'entity': 'Titans', 'salience': 0.5078485012054443, 'score': 0.0, 'magnitude': 0.0}, {'entity': 'NFL', 'salience': 0.17606110870838165, 'score': 0.0, 'magnitude': 0.0}, {'entity': 'Dallas Cowboys', 'salience': 0.13596995174884796, 'score': 0.0, 'magnitude': 0.0}, {'entity': 'game', 'salience': 0.09261608868837357, 'score': 0.0, 'magnitude': 0.0}, {'entity': 'Aaron Rodgers', 'salience': 0.08750434964895248, 'score': 0.0, 'magnitude': 0.0}]
--------------------
Negative Comment
[{'entity': 'Titans', 'salience': 1.0, 'score': -0.699999988079071, 'magnitude': 0.699999988079071}]
--------------------
Positive Comment with Negative Component
[{'entity': 'Titans', 'salience': 0.6374751329421997, 'score': 0.20000000298023224, 'magnitude': 0.20000000298023224}, {'entity': 'team', 'salience': 0.27688688039779663, 'score': 0.4000000059604645, 'magnitude': 0.4000000059604645}, {'entity': 'player-guy', 'salience': 0.08563800156116486, 'score': 0.20000000298023224, 'magnitude': 0.20000000298023224}]
--------------------
Positive Comment
[{'entity': 'Titans', 'salience': 0.695039689540863, 'score': 0.8999999761581421, 'magnitude': 0.8999999761581421}, {'entity': 'team', 'salience': 0.30496031045913696, 'score': 0.8999999761581421, 'magnitude': 0.8999999761581421}]
Anwendung auf NFL-Daten#
In diesem Abschnitt wird die Anwendung der oben beschriebenen Funktionen auf die NFL-Daten erstellt. Durch die Limitierung von 10.000 Abrufen der Youtube API wird das Scrapping auf mehrere Tage verteilt. Um bereits ausgelesene Footballspiele zu erkennen, wird das Dokument gelöscht, sobald die darauf basierenden Dokumente mit Kommentaren und Entitäten erstellt wurden.
Auslesen von Dokumenten ohne Video-ID aus mongodb
Zusammensetzen des Videotitels aus den Daten
Abrufen der Video-ID
Abrufen der Kommentare
Iterieren über die Kommentare
Anlegen eines Dokuments je Entität
Löschen des Dokuments ohne Video-ID (siehe Schritt 1)
Mit try-except werden Fehlermeldungen zu nicht englischsprachigen Kommentaren abgefangen. Diese werden für die Sentimentanalyse nicht verwendet.
myList = mycoll.find({'videoID':{'$exists':False}})[0:2] # Anzahl der Dokumente = 2
counter = 0
for doc in myList:
mongo_obj_id = doc['_id'] # Store ObjectID from mongoDB
myTitle = doc['team1']+' '+doc['team2']+' '+doc['week']+' Highlights | NFL 2021' # Generate Title String to retrieve videoID
vid_id = get_videoID_by_title(myTitle)
for comment in get_comments(vid_id):
counter += 1
myDict = dict()
# Retrieve old information
myDict = doc
myDict['videoID'] = vid_id
# Add new information / generate one doc per entity
myDict['comment'] = comment
try:
entList = get_entity_sentiment(comment)
for ent in entList:
del myDict['_id'] # Delete ObjectId that is returned after first insert_one() function call
myDict['entity'] = ent['entity']
myDict['salience'] = ent['salience']
myDict['score'] = ent['score']
myDict['magnitude'] = ent['magnitude']
mycoll.insert_one(myDict)
except:
print('Comment is not in English.') # Catch Comments that are not in English. Those cannot be analysed by our sentiment-function.
mycoll.delete_one({'_id':ObjectId(mongo_obj_id)}) # Delete Object bei ID
print('Anzahl Kommentare:',counter)
Comment is not in English.
Anzahl Kommentare: 40
Nachfolgend werden drei Ziel-Dokumente für einen Kommentar angezeigt, jeweils mit der erkannten Entität. Inwiefern die Entität verwendet werden kann, wird im Kapitel Analyse erläutert.
myList = list(mycoll.find({'videoID':{'$exists':True}})[0:3])
myList
[{'_id': ObjectId('638b4650fa6daae7e3705e40'),
'team1': 'Cowboys',
'score1': '16',
'team2': 'Broncos',
'score2': '30',
'year': '2021',
'week': 'Week 9',
'videoID': 'fBJx86Q9JkQ',
'comment': 'This Cowboys team was 6-1? Getting absolutely dumpstered by a mediocre at best Broncos team? Strange.',
'entity': 'Cowboys',
'salience': 0.3155188262462616,
'score': 0.0,
'magnitude': 0.0},
{'_id': ObjectId('638b4650fa6daae7e3705e42'),
'team1': 'Cowboys',
'score1': '16',
'team2': 'Broncos',
'score2': '30',
'year': '2021',
'week': 'Week 9',
'videoID': 'fBJx86Q9JkQ',
'comment': 'This Cowboys team was 6-1? Getting absolutely dumpstered by a mediocre at best Broncos team? Strange.',
'entity': 'Broncos',
'salience': 0.03218727558851242,
'score': -0.800000011920929,
'magnitude': 0.800000011920929},
{'_id': ObjectId('638b4650fa6daae7e3705e43'),
'team1': 'Cowboys',
'score1': '16',
'team2': 'Broncos',
'score2': '30',
'year': '2021',
'week': 'Week 9',
'videoID': 'fBJx86Q9JkQ',
'comment': 'This Cowboys team was 6-1? Getting absolutely dumpstered by a mediocre at best Broncos team? Strange.',
'entity': 'Strange',
'salience': 0.022530527785420418,
'score': 0.0,
'magnitude': 0.0}]